4 Results - Differential Expression
To compare lexicons for male and female characters across all authors, I used DESeq2 to compare word frequencies across character gender. This process is computationally intensive, so I only included the 10,000 most frequent words and 4000 characters with the highest read depth (the entire dataset includes 25,000 characters across 6000 books). Result are visualized in an interactive plot (fig 4.1). Differentially expressed words for female (table 6.1) and male (table 6.2) characters are included in the supplemental data.
Figure 4.1: Differential word frequency by character gender
Next, I compared lexicons for male and female authors (fig 4.2). A subjective assessment of the data suggests that these differences may largely are due to genre. Differentially expressed words are included in supplemental data (tables 6.3 and 6.4 ).
Figure 4.2: Differential word frequency by author gender
Words that are more frequently associated with male characters are also more frequently used by male authors (fig 4.3). The is likely a consequence of male authors more frequently writing male characters (fig (fig:characterCounts)). I haven’t figured out the best way to control for this difference. I might try weighting word frequency by character gender frequency.
Figure 4.3: Correlation between word frequency across character and author gender
Next, I trained an ensemble learner to classify characters (table 4.2) and authors (table 4.1) by gender using normalized word counts from DESeq2. This model is disturbingly good at classifying author gender. A bad interpretation would ignore confounding variables such as gender imbalances in genre. Goodreads.com tags are probably rather biased by author gender, and genre tags alone are only slightly less accurate at predicting author gender than the text (table 3.1). I’m not sure how to control for this.
The distinction between male and female characters was slightly larger for male authors (fig. 4.4).
| Predicted Male | Predicted Female | |
|---|---|---|
| Male Authors | 1522 | 298 |
| Female Authors | 292 | 1736 |
| Predicted Male | Predicted Female | |
|---|---|---|
| Male Characters | 4262 | 738 |
| Female Characters | 806 | 4194 |
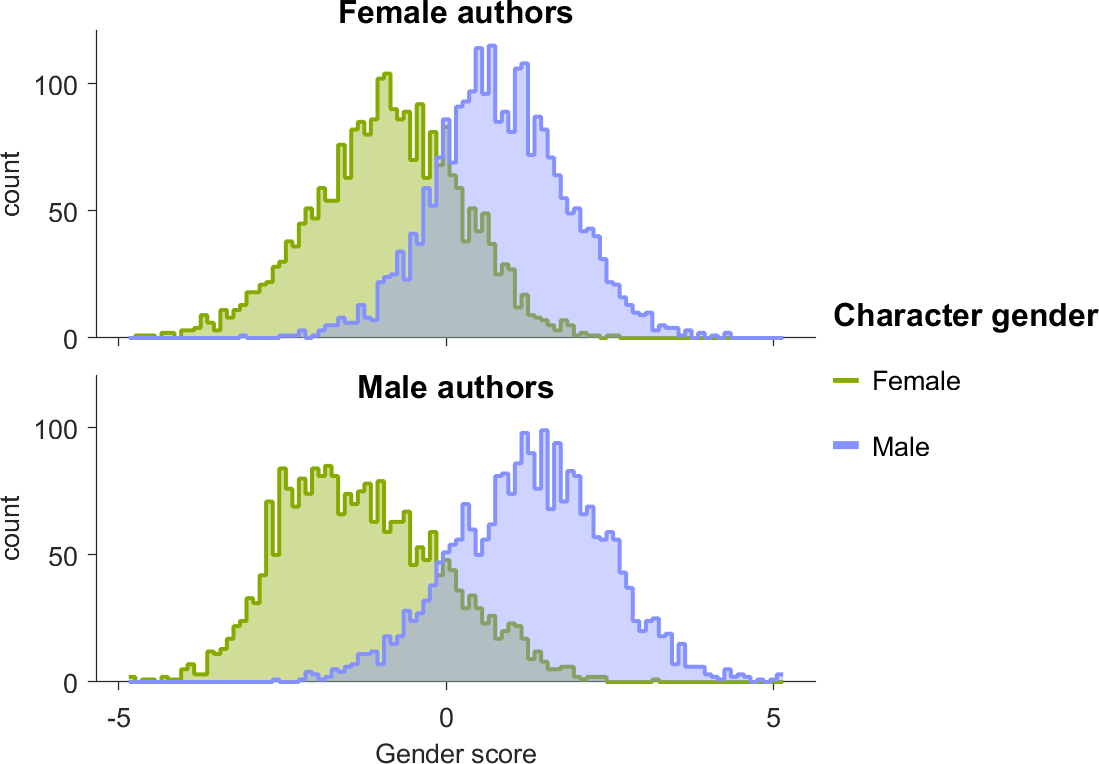
Figure 4.4: Character gender score using bag of words.